Warning
All the operators and their functionality within this repository have been deprecated and will not receive further updates. Read more about the deprecation in the Deprecation Notice section below.
Deprecation Notice#
With the release 0.3.0 of the astro-provider-databricks package, this provider stands deprecated and will
no longer receive updates. We recommend migrating to the official apache-airflow-providers-databricks>=6.8.0 for the latest features and support.
For the operators and sensors that are deprecated in this repository, migrating to the official Apache Airflow Databricks Provider
is as simple as changing the import path in your DAG code as per the below examples.
Previous import path used |
Newer import path to use |
|---|---|
from astro_databricks.operators.notebook import DatabricksNotebookOperator |
from airflow.providers.databricks.operators.databricks import DatabricksNotebookOperator |
from astro_databricks.operators.workflow import DatabricksWorkflowTaskGroup |
from airflow.providers.databricks.operators.databricks_workflow import DatabricksWorkflowTaskGroup |
from astro_databricks.operators.common import DatabricksTaskOperator |
from airflow.providers.databricks.operators.databricks import DatabricksTaskOperator |
from astro_databricks.plugins.plugin import AstroDatabricksPlugin |
from airflow.providers.airflow.providers.databricks.plugins.databricks_workflow import DatabricksWorkflowPlugin |
Astro Databricks Provider#
This is a provider for running Databricks Jobs on Airflow created by Astronomer.
Databricks Workflow TaskGroup#
The Databricks Workflow TaskGroup is a recent addition to the Databricks platform that allows users to easily create and manage Databricks Jobs with multiple notebooks, SQL statements, python files, etc. One of the biggest benefits offered by Databricks Jobs is the use of Job Clusters, which are significantly cheaper than all-purpose clusters.
With the DatabricksWorkflowTaskGroup, users can take advantage of the cost savings offered by using Jobs clusters, while also having the flexibility and multi-platform capabilities of Airflow.
The DatabricksWorkflowTaskGroup is designed to look and function like a standard task group, with the added ability to include specific Databricks arguments. An example of how to use the DatabricksWorkflowTaskGroup can be seen in the following code snippet:
task_group = DatabricksWorkflowTaskGroup(
group_id=f"test_workflow_{USER}_{GROUP_ID}",
databricks_conn_id=DATABRICKS_CONN_ID,
job_clusters=job_cluster_spec,
notebook_params={"ts": "{{ ts }}"},
notebook_packages=[
{
"pypi": {
"package": "simplejson==3.18.0", # Pin specification version of a package like this.
"repo": "https://pypi.org/simple", # You can specify your required Pypi index here.
}
},
],
extra_job_params={
## Commented below to avoid spam; keeping this for example purposes.
# "email_notifications": {
# "on_start": [DATABRICKS_NOTIFICATION_EMAIL],
# },
"webhook_notifications": {
"on_start": [{"id": DATABRICKS_DESTINATION_ID}],
},
},
)
with task_group:
notebook_1 = DatabricksNotebookOperator(
task_id="notebook_1",
databricks_conn_id=DATABRICKS_CONN_ID,
notebook_path="/Shared/Notebook_1",
notebook_packages=[{"pypi": {"package": "Faker"}}],
source="WORKSPACE",
job_cluster_key="Shared_job_cluster",
execution_timeout=timedelta(seconds=600),
)
notebook_2 = DatabricksNotebookOperator(
task_id="notebook_2",
databricks_conn_id=DATABRICKS_CONN_ID,
notebook_path="/Shared/Notebook_2",
source="WORKSPACE",
job_cluster_key="Shared_job_cluster",
notebook_params={"foo": "bar", "ds": "{{ ds }}"},
)
notebook_1 >> notebook_2
At the top-level Taskgroup definition, users can define workflow-level parameters such as notebook_params,
notebook_packages or spark_submit_params. These parameters will be applied to all tasks within the Workflow.
Inside of the taskgroup, users can define the individual tasks that make up the workflow. Currently the only officially
supported operator is the DatabricksNotebookOperator, but other operators can be used as long as they contain the
convert_to_databricks_workflow_task function. In the future we plan to support SQL and python functions via the
Astro SDK.
For each notebook task, packages defined with the notebook_packages parameter defined at the task level are
installed and additionally, all the packages supplied via the workflow-level parameter notebook_packages are also
installed for its run. The collated notebook_packages list type parameter is transformed into the libraries list
type parameter accepted by the Databricks API and a list of supported library types and their format for the API
specification is mentioned at the Databricks documentation.
Warning
Make sure that you do not specify duplicate libraries across workflow-level and task-level notebook-packages as
the Databricks task will then fail complaining about duplicate installation of the library.
Retries#
When repairing a Databricks workflow, we need to submit a repair request using Databricks’ Jobs API. One core difference between how Databricks repairs work v.s. Airflow retries is that Airflow is able to retry one task at a time, while Databricks expects a single repair request for all tasks you want to rerun (this is because Databricks starts a new job cluster for each repair request, and jobs clusters can’t be modified once they are started).
To avoid creating multiple clusters for each failed task, we do not use Airflow’s built-in retries. Instead, we offer a “Repair all tasks” button in the “launch” task’s grid and graph node on the Airflow UI. This button finds all failed and skipped tasks and sends them to Databricks for repair. By using this approach, we can save time and resources, as we do not need to create a new cluster for each failed task.
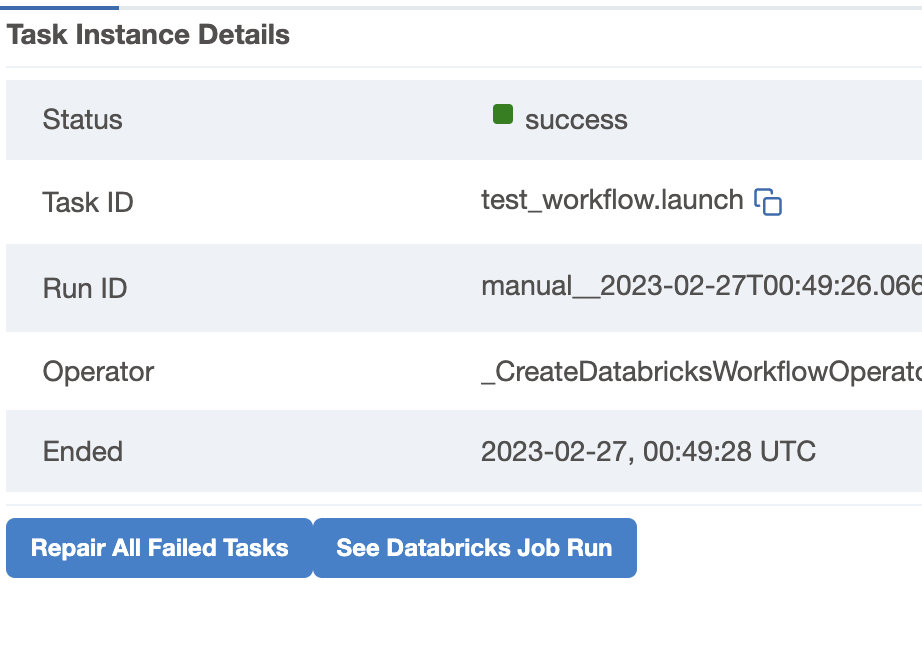
In addition to the “Repair all tasks” button, we also provide a “Repair single task” button to repair a specific failed task. This button can be used if we want to retry a single task rather than all failed tasks.
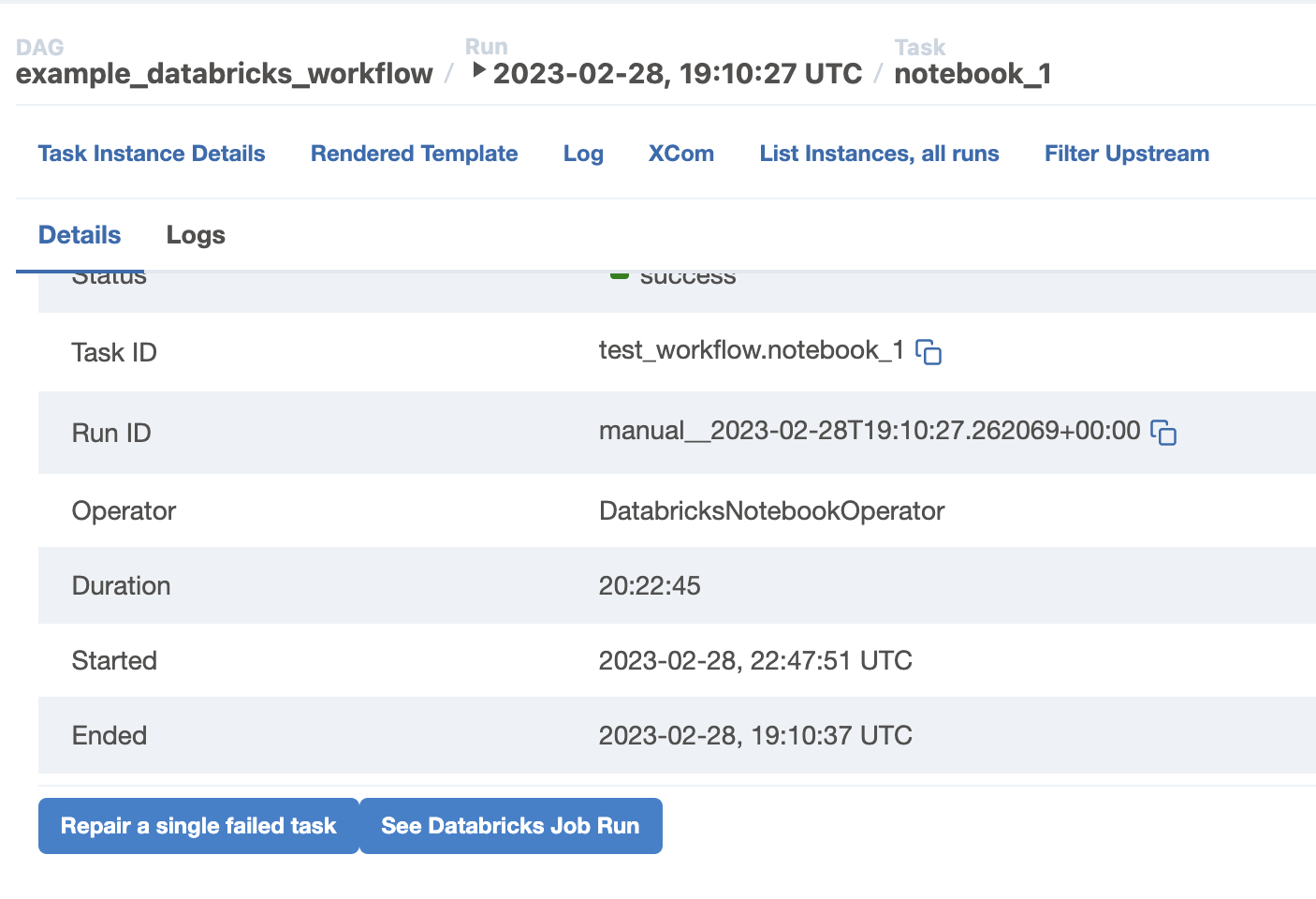
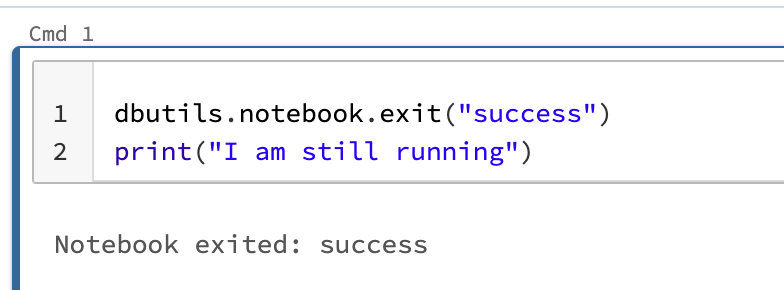
It is important to note that Databricks does not support repairing a task that has a failing upstream. Therefore, if we want to skip a notebook and run downstream tasks, we need to add a “dbutils.notebook.exit(“success”)” at the top of the notebook inside of databricks. This will ensure that the notebook does not run and the downstream tasks can continue to execute.
Limitations#
The DatabricksWorkflowTaskGroup is currently in beta and has the following limitations:
Since Databricks Workflow Jobs do not support dynamic parameters at the task level, we recommend placing dynamic parameters at the TaskGroup level (e.g. the
notebook_paramsparameter in the example above). This will ensure that the job is not changed every time the DAG is run.If you plan to run the same DAG multiple times at the same time, make sure to set the
max_concurrencyparameter to the expected number of concurrent runs.
Configuration#
By default, the Databricks provider uses the Databricks API version 2.1 for all API calls. This can be overridden by setting an environment variable DATABRICKS_JOBS_API_VERSION.