Welcome to the Ray provider documentation!¶
Warning
Discontinuation of project. This project is no longer actively maintained by Astronomer. Development has been paused and we are not accepting new contributions, bug fixes or releases. The code is kept here for historical purposes; it may not work with the latest dependencies or platforms and could contain security vulnerabilities, so Astronomer can’t offer guarantees or warranties for its use.
If you run Ray on Google Cloud, the official Apache Airflow Google provider
(apache-airflow-providers-google) ships Ray operators that cover a subset of this provider:
cluster lifecycle on Vertex AI (CreateRayClusterOperator, ListRayClustersOperator,
GetRayClusterOperator, UpdateRayClusterOperator, DeleteRayClusterOperator) and Ray job
management (RaySubmitJobOperator, RayStopJobOperator, RayDeleteJobOperator,
RayGetJobInfoOperator, RayListJobsOperator). This provider is Kubernetes-generic, so the
Google operators are a Google Cloud-specific alternative, not a drop-in replacement.
If you’re interested in adopting or stewarding this project, reach us at oss@astronomer.io. Thanks for being part of the open-source journey and helping keep great ideas alive!
This repository contains modules for integrating Apache Airflow® with Ray, enabling the orchestration of Ray jobs from Airflow DAGs. It includes a decorator, two operators, and one trigger designed to efficiently manage and monitor Ray jobs and services.
Benefits of using this provider include:
Integration: Incorporate Ray jobs into Airflow DAGs for unified workflow management.
Distributed computing: Use Ray’s distributed capabilities within Airflow pipelines for scalable ETL, LLM fine-tuning etc.
Monitoring: Track Ray job progress through Airflow’s user interface.
Dependency management: Define and manage dependencies between Ray jobs and other tasks in Airflow DAGs.
Resource allocation: Run Ray jobs alongside other task types within a single pipeline.
Table of Contents¶
Quickstart¶
See the Getting Started page for detailed instructions on how to begin using the provider.
Why use Airflow with Ray?¶
Value creation from data in an enterprise environment involves two crucial components:
Data Engineering (ETL/ELT/Infrastructure Management)
Data Science (ML/AI)
While Airflow excels at orchestrating both, data engineering and data science related tasks through its extensive provider ecosystem, it often relies on external systems when dealing with large-scale (100s GB to PB scale) data and compute (GPU) requirements, such as fine-tuning & deploying LLMs etc.
Ray is a particularly powerful platform for handling large scale computations and this provider makes it very straightforward to orchestrate Ray jobs from Airflow.
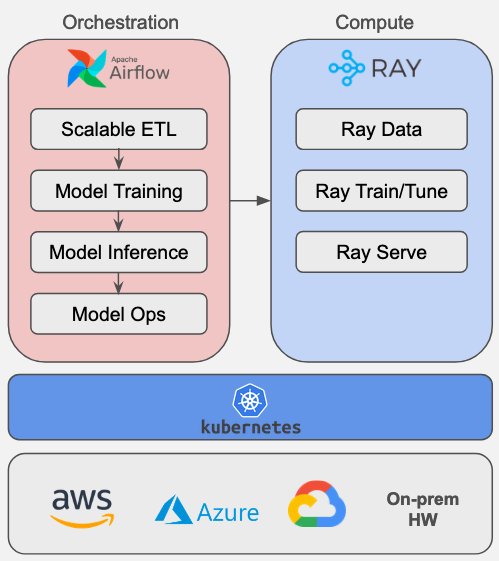
The architecture diagram above shows that we can run both, Airflow and Ray side by side on Kubernetes to leverage the best of both worlds. Airflow can be used to orchestrate Ray jobs and services, while Ray can be used to run distributed computations.
Use Cases¶
Scalable ETL: Orchestrate and monitor Ray jobs to perform distributed ETL for heavy data loads on on-demand compute clusters using the Ray Data library.
Model Training: Schedule model training or fine-tuning jobs on flexible cadences (daily/weekly/monthly). Benefits include:
Optimize resource utilization by scheduling Ray jobs during cost-effective periods
Trigger model refresh based on changing business conditions or data trends
Model Inference: Inference of trained or fine-tuned models can be handled in two ways:
Batch Inference jobs can be incorporated into Airflow DAGs for unified workflow management and monitoring
Real time models (or online models) that use Ray Serve can be deployed using the same operators with
wait_for_completion=False
Model Ops: Leverage Airflow tasks following Ray job tasks for model management
Deploy models to a model registry
Perform champion-challenger analysis
Execute other model lifecycle management tasks
Components¶
Decorators¶
@ray.task(): Simplifies integration by decorating task functions to work seamlessly with Ray.
Operators¶
SetupRayCluster: Sets up or Updates a ray cluster on kubernetes using a kubeconfig input provided through the Ray connection
DeleteRayCluster: Deletes an existing Ray cluster on kubernetes using the same Ray connection
SubmitRayJob: Submits jobs to a Ray cluster using a specified host name and monitors its execution
Hooks¶
RayHook: Sets up methods needed to run operators and decorators, working with the ‘Ray’ connection type to manage Ray clusters and submit jobs.
Triggers¶
RayJobTrigger: Monitors asynchronous job execution submitted via the
SubmitRayJoboperator or using the@ray.task()decorator and prints real-time logs to the the Airflow UI
Getting Involved¶
Platform |
Purpose |
Estimated Response Time |
|---|---|---|
General inquiries and discussions |
< 3 day |
|
Bug reports and feature requests |
< 1-2 days |
|
Quick questions and real-time chat. Join (#airflow-ray) |
< 12 hrs |
Changelog¶
We follow Semantic Versioning for releases. Check CHANGELOG.rst for the latest changes.
Contributing Guide¶
All contributions, bug reports, bug fixes, documentation improvements, enhancements are welcome.
A detailed overview an how to contribute can be found in the Contributing Guide
This project follows Astronomer’s Privacy Policy
